Capítulo 2 Metodologia
Toda pesquisa jurimétrica passa necessariamente por três etapas: listagem de processos, coleta de dados e análise estatística. A etapa da listagem envolve encontrar os números identificadores dos processos que fazem parte da pesquisa, considerando o escopo definido. Já a etapa de coleta envolve acessar os processos através de seus números identificadores, obtendo as informações que são relevantes para o estudo. A terceira etapa envolve a análise estatística dos dados coletados, realizando os cruzamentos necessários para atingir os objetivos da pesquisa.
Antes de listar os processos, entretanto, devemos ter um escopo bem definido. No nosso caso, o escopo inicial considerou as recuperações judiciais no Rio de Janeiro distribuídas a partir de 2006. Após a listagem de processos, o escopo foi adaptado para o período de 2010 a 2018, por dois motivos.
Em primeiro lugar, é importante restringir o escopo para comparar as conclusões do Rio de Janeiro e São Paulo. A versão mais recente do Observatório da Insolvência de São Paulo2 considera processos distribuídos entre 2010 e julho de 2017.
Em segundo lugar, a restrição serve para reduzir os problemas envolvendo a análise de processos físicos e para evitar a análise de casos muito recentes. De um lado, os processos físicos geram problemas à análise, porque eles possuem muitos dados faltantes. O problema é mitigado ao aplicar um filtro a partir de 2010 porque foi a partir de então que o processo eletrônico passou a ser implementado no TJ/RJ, após a Resolução 16 de 30 de Novembro de 20093. Do outro lado, casos recentes geram problemas porque eles ainda não finalizaram a fase de negociação. Isso pode distorcer os valores relacionados ao tempo. Por isso, também foram considerados filtros para processos recentes.
Uma vez definido o escopo, podemos passar à listagem de processos.
2.1 Listagem de processos
A listagem de processos envolve três passos: identificação das fontes de dados, acesso aos processos e aplicação dos filtros de escopo. O primeiro passo serve para encontrar todos os meios para consulta dos processos de interesse. O segundo passo envolve desenvolver métodos computacionais para acessar e consolidar as informações a respeito desses processos. O último passo envolve adequar os dados resultantes ao escopo da pesquisa, excluindo casos que não farão parte da população em análise.
A primeira tentativa para obter os dados de PRJ foi entrando em contato com o Tribunal de Justiça do Rio de Janeiro (TJRJ). No entanto, após diversas trocas de mensagens entre a ABJ e a equipe técnica do TJRJ, os dados acabaram não sendo disponibilizados pelo tribunal. A única informação disponibilizada foi o volume agregado de ações, mas sem uma descrição clara dos critérios de inclusão e exclusão utilizados para obtenção da base. Por isso, a estratégia de pedir dados diretamente do tribunal foi descartada.
Após um tempo de desenvolvimento de rotinas computacionais4, definimos que a fonte de dados utilizada para listar os processos seria os Diários de Justiça Eletrônicos (DJE) disponibilizados no site do TJRJ. Tratam-se de arquivos PDF com milhares de páginas, contendo informações de toda a tramitação processual diária do estado. Os arquivos foram baixados utilizando-se técnicas de raspagem de dados e transformados em texto para permitir a identificação de processos.
A identificação dos processos consiste em filtrar as páginas dos DJEs que contêm alguma menção a processos de recuperações judiciais. O filtro considerou as expressões regulares “recupera”, “falência” ou “falida” para obtenção das informações. As expressões regulares ignoram maiúsculas e minúsculas e consideram palavras com ou sem acento. As páginas assim obtidas foram então processadas para a listagem de 1.975.876 números de processos.
Finalmente, a filtragem de escopo envolveu a consulta automatizada dos milhões de processos identificados no passo anterior na consulta do TJRJ. Foram mantidos somente os processos contendo os termos de “Recuperação Judicial” nos campos classe, assunto ou ação, como mostra a Figura 2.1.
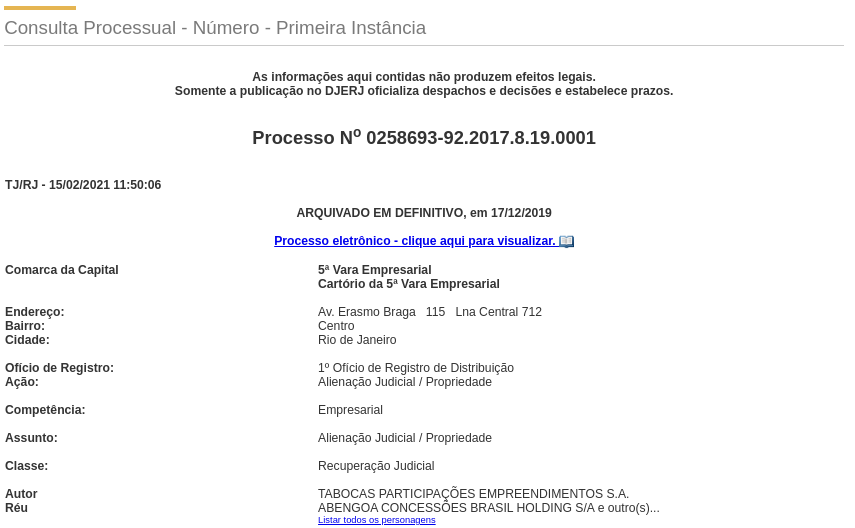
Figura 2.1: Exemplo de consulta processual no TJRJ.
Infelizmente, a taxonomia de classe e assunto dos processos não é específica o suficiente para identificar de forma clara os processos principais dos PRJ. Por esse motivo, foi necessário verificar manualmente se os processos listados eram, de fato, recuperações. Nesse processo, mais de 90% dos processos listados foram descartados.
Outro problema característico do TJRJ foi o impacto da recuperação judicial da Oi Telemar S/A. Por envolver muitos credores, o tribunal foi inundado de ações de habilitação de crédito, muitas vezes sem a denominação do tipo de processo. Por isso, foi necessário aplicar filtros específicos para excluir processos relacionados à Oi.
Ao final da aplicação de filtros automatizados e manuais, foram identificados 323 processos principais de recuperação judicial. Esses casos podem ser entendidos como uma amostra representativa do total de PRJs do tribunal, suficiente para obtenção de resultados confiáveis na parte de análise. Os casos não contemplados por essa metodologia usualmente apresentam dificuldades de acesso por DJEs ou outros problemas de documentação na classe, assunto e tipo de ação disponibilizadas na consulta processual.
Em um recente levantamento disponibilizado por pesquisadores da UERJ5, identificamos mais 81 processos de recuperação judicial que não faziam parte do levantamento anterior. Os números serão considerados em fases posteriores do Observatório da Insolvência - Rio de Janeiro.
2.2 Coleta
A coleta de dados envolve a leitura dos documentos de todos os processos resultantes da aplicação dos filtros de escopo e o preenchimento de fichas de classificação. Para isso, adotou-se uma metodologia em três passos: pré-teste, classificação e diagnóstico.
No pré-teste, foram analisados 30 casos no total, sendo cada processo analisado por três pesquisadores distintos. O objetivo do pré-teste é compreender questões com problemas de interpretabilidade ou alto grau de subjetividade e antecipar possíveis problemas do questionário. A partir do pré-teste, alguns aprimoramentos foram realizados no formulário de classificação final, como a remoção de questões que não poderiam ser respondidas a partir da análise dos autos. O pré-teste foi finalizado em dezembro de 2019.
Durante a etapa de classificação, cada pesquisador recebeu um conjunto de processos para analisar. Dessa vez, cada processo foi classificado por apenas uma pesquisadora ou pesquisador. O formulário de classificação aplicado utilizou tecnologia Google Forms, pela sua facilidade com a integração com as ferramentas computacionais da ABJ. O formulário possui mais de 50 campos, sendo uma parte preenchida automaticamente com metadados do processo (como número do processo e classe processual) e parte se desdobrava em vários campos. O formulário também envolve planilhas Excel auxiliares para inclusão de todas as informações das partes, AGCs e características dos planos de recuperação. As planilhas possuem controle de entrada de informações, com categorias bem definidas para cada campo sempre que possível, com o objetivo de evitar inconsistências na análise dos dados. Os casos foram acessados através da consulta processual do TJRJ. Esta etapa foi foi realizada entre maio e julho de 2020.
Durante a etapa de diagnóstico, os estatísticos da equipe extraíram a base de dados construída pelos pesquisadores buscando inconsistências na classificação. Os procedimentos de detecção de inconsistência visavam identificar datas incoerentes, informações conflitantes e lacunas na base. Os processos com problemas retornaram aos pesquisadores e foram corrigidos manualmente. O resultado foi uma base de dados final, preparada para análise.
2.3 Análise
O fluxo de obtenção, arrumação e análise de dados segue o ciclo da ciência de dados, descrito na Figura 2.2. O ciclo divide o processo de aprendizado analítico em seis etapas, descritas a seguir.
Primeiro, o formulário de classificação e as planilhas auxiliares são extraídas. Em seguida, os dados são arrumados, para mitigar problemas de padronização, obter as variáveis de interesse e excluir casos que estão fora do escopo de análise, excluir casos que estão fora do escopo de análise (no caso, a exclusão de recuperações judiciais que não estejam entre 2010 e 2018), produzindo o que se define como base de dados analítica. A base completa possui 323 casos, sendo que somente 313 foram considerados, de acordo com o recorte de processos distribuídos entre 2010 e 2018.
A base analítica foi então transformada para produzir as tabelas e gráficos e utilizada como insumo para o ajuste de modelos estatísticos. Finalmente, os resultados obtidos foram comunicados através do presente relatório e de um dashboard interativo, disponível no site do Observatório da Insolvência - Rio de Janeiro.
, adaptado do livro [R for Data Science](https://r4ds.had.co.nz).](assets/img/ciclo-ds.png)
Figura 2.2: Ciclo da ciência de dados. Fonte: Curso-R, adaptado do livro R for Data Science.
O estudo envolveu majoritariamente análises descritivas, como tabelas e gráficos. O propósito das visualizações é verificar as principais perguntas da pesquisa e trazer sumários úteis para a discussão sobre os processos.
Para responder algumas perguntas específicas, foi necessário utilizar modelos estatísticos. Modelos de análise de sobrevivência (Colosimo and Giolo 2006) foram utilizados para tratar adequadamente os tempos dos processos, que podem ser censurados por não apresentarem determinado evento de interesse no momento de coleta.
Todas as análises foram realizadas utilizando-se o software estatístico R, na versão 4.2.0. Os códigos que levam a base de dados analítica para os resultados da pesquisa são reprodutíveis, podendo ser utilizados em projetos futuros de atualização da base.