Capítulo 2 Metodologia
Toda pesquisa jurimétrica passa necessariamente por três etapas: listagem de processos, coleta de dados e análise estatística. A etapa da listagem envolve encontrar os números identificadores dos processos que fazem parte da pesquisa, considerando o escopo definido. Já a etapa de coleta envolve acessar os processos através de seus números identificadores, obtendo as informações que são relevantes para o estudo. A terceira etapa envolve a análise estatística dos dados coletados, realizando os cruzamentos necessários para atingir os objetivos da pesquisa.
2.1 Listagem de processos
A listagem de processos envolve três passos principais: identificação das fontes de dados, acesso aos processos e aplicação dos filtros de escopo. O primeiro passo envolve encontrar todos os meios para consulta dos processos de interesse. O segundo passo envolve desenvolver métodos computacionais para acessar e consolidar as informações a respeito desses processos. O último passo envolve adequar os dados resultantes ao escopo da pesquisa, excluindo casos que não farão parte da população em análise.
2.1.1 Fontes de dados
A ferramenta principal para a listagem de processos é a ferramenta de consulta de acródãos do CRSFN, presente no site do Banco Central do Brasil1. A partir desta ferramenta, pudemos extrair todos os acórdãos já produzidos pelo CRSFN. Isso garante que todos os processos encontrados sejam processos já finalizados, fazendo da pesquisa uma pesquisa retrospectiva. Apesar de a pesquisa ser retrospectiva, não existe um critério a priori de delimitação do escpopo temporal, de forma que não construímos uma janela de análise preliminar, nem para a data de distribuição dos processos, nem para a data de saída deles. Tentamos obter todos os processos que finalizaram no CRSFN até a data da extração dos processo, isto é, todos os processos já finalizados até 02 de março de 2022.

Figura 2.1: Ferramenta de consulta do PAS no CRSFN.
2.1.2 Acesso
A ferramenta do BCB de consulta aos acórdãos do CRSFN retorna muitas decisões acórdãos, sem nenhum metadado. Construímos, então, um scraper, que pegou todos os textos de todos os acórdãos que retornaram na pesquisa e guardou os textos em um repositório.
Essa base de textos, entretanto, ainda não consegue listar os processos exatamente, pois os números dos processos não estão organizados. Entretanto, pelo texto, é possível extrair informações preliminares de todos os acórdãos. No texto podemos encontrar o cabeçalho dos acórdãos, que pode ser melhor visualizado na Figura 2.2.

Figura 2.2: Exemplo de um cabeçalho dos acórdãos do CRSFN. Neste exemplo, vemos como a informação do número dos processos aparece nos acórdãos.
Vemos nesta imagem que cada acórdão continha as seguintes informações de capa, em ordem de aparição:
- O número da sessão em que o processo foi julgado;
- O número SEI do processo na CRSFN;
- O número do processo na primeira instância, seja no Banco do Brasil (BCB), seja na Comissão de Valores Mobiliários (CVM);
- O tipo de recurso (recurso voluntário ou recurso de ofício);
- O nome das partes e suas funções no processo;
- A ementa do processo.
Duas dessas informações representam o que buscávamos: o número SEI do processo na CRSFN e o número do processo na CVM. Ambas informações são igualmente importantes, pois, neste projeto, queremos analisar as continuidades entre o julgamento na CVM e o julgamento no CRSFN, então era importante ter o número identificador do processo nas duas instâncias. A partir dos textos dos documentos, então, extraímos os dois números processuais de interesse usando expressões regulares, construindo, assim, a base de processos.
2.2 Coleta
Com a lista de processos pronta, pudemos prosseguir para a coleta das informações de cada processo. Esta etapa se subdvidiu em duas formas de coleta de dados distintas, a coleta manual e a coleta automática. A seguir, detalhamos cada uma dessas coletas.
2.2.1 Coleta manual
A coleta manual se baseou na classificação individual de cada processo a partir de um formulário de classificação. Vamos detalhar as etapas até a classificação manual, que são, em ordem: a criação do formulário de classificação; a validação do formulário com o pré-teste; o preenchimento do formulário.
2.2.1.1 Criação do formulário
O formulário de classificação foi pensado a partir das perguntas norteadoras. É um formulário planejado para ser respondido por processo, ou seja, cada resposta do formulário representa um processo distinto. Ele foi feito utilizando tecnologia Google Forms, pela sua facilidade com a integração com as ferramentas computacionais da ABJ.
O formulário é curto, com apenas 14 campos. Além do formulário, no entanto, há uma planilha adicional, que contém mais 53 campos. Essas informações estão separadas pois, enquanto o formulário faz perguntas sobre o processo como um todo, a planilha faz perguntas específicas sobre o julgamento de cada uma das partes do processo. Assim, diferenciamos a planilha do formulário por sua unidade amostral. Enquanto este representa um processo, de forma que cada linha significa um processo, aquela representa um processo-parte-tipo de recurso. A unidade amostral da planilha é um pouco mais complexa, por isso, merece mais explicação.
Cada processo no CRSFN pode julgar múltiplas partes. Essas partes são as mesmas que participaram do processo administrativo sancionador na CVM. Cada uma dessas partes recebe um julgamento individualizado, de forma que uma pode ser absolvida, enquanto outras serem julgadas, e as penalidade aplicadas a cada parte também podem ser diferentes. Por essa razão a unidade amostral da planilha não é apenas o processo, mas é uma parte-processo.
Isso, entretanto, ainda não explica a unidade amostral inteira, que não é simplesmente ‘parte-processo’, mas sim ‘parte-processo-tipo de recurso’. O que acontece é que, além de cada processo ter julgamentos distintos para partes distintas, é possível que essas partes apareçam no processo por causa de tipos de recursos diferentes. Por exemplo, se, na CVM, duas partes foram acusadas, e uma delas foi absolvida, mas a outra foi condenada, então à primeira parte, caberá recurso de ofício, enquanto à segunda, caberá recurso voluntário. É importante sabermos qual é o tipo de recurso que trouxe uma parte ao processo no CRSFN porque isso muda a interpretação do julgamento do acórdão. Por exemplo, uma decisão totalmente procedente em um recurso voluntário significa a absolvição de uma parte que fora condenada em primeira instância; mas uma decisão totalmente procedente em um recurso de ofício significa justamente o contrário: significa a condenação de uma parte que fora absolvida em primeira instância. Por isso é importante termos como unidade de análise o conjunto ‘parte-processo-tipo de recurso’.
Em resumo, existem duas ferramentas de classificação dos processos:
- O formulário, cuja unidade de análise é o processo e contém 14 campos de resposta.
- A planilha, cuja unidade de análise é uma parte, por processo, por tipo de recurso, e contém 53 campos de resposta.
2.2.1.2 Validação do formulário
Tanto o formulário de classificação como a planilha de partes passaram por um processo de validação antes de serem preenchidos. Este procedimento de validação é chamado “pré-teste” e consiste em amostrar aleatoriamente alguns casos que deverão ser analisados, distribuido os processos para toda a equipe de pequisa. Essa equipe irá, portanto, classificar os mesmos processos, para (1) identificar possíveis inconsistências lógicas no formulário e na planilha; (2) identificar questões de fato que aparecem nos processos, mas que não estão contempladas nas ferramentas de coleta de dados. Um exemplo de inconsistência lógica no formulário é se ele pergunta “O processo foi considerado prioritário?”, a pessoa responde que “Não” e, logo em seguida, aparece a pergunta “Qual foi a hipótese de prioridade do processo?”. Já um exemplo de questões factuais que poderiam ter ficado de fora do formulário/planilha diz respeito às penalidades possíveis. Na planilha de partes inicial, havia perguntas sobre a mudança da penalidade de multa em relação à primeira instância. As colunas da planilha indagavam se a penalidade aplicada na CVM era de multa, qual era o valor da multa inicial, como essa multa foi modificada (ela foi extinta, reduzida ou se manteve igual) e qual foi o seu valor final. Entretanto, não havia sido pensado, na concepção da planilha de partes, a hipótese de uma multa ser convolada em outro tipo de pena, tal como inabilitação ou suspensão de um cargo. Assim, a planilha teve de ser ajustada.
A etapa de verificação do formulário/planilha deve ser sempre prévia à coleta de dados, pois, uma vez que se iniciam as classificações, não é mais desejável alterar, nem o formulário, nem a planilha, pois isso geraria uma discrepância na classificação dos casos. Por exemplo, imaginemos que percebemos, não no pré-teste, mas apenas depois de termos preenchido metade dos processos listados que havia a possibilidade de convolação da pena de multa em outros tipos de penas e decidíssemos, então, modificar a planilha de classificação para abarcar esta hipótese. Se isso acontecesse desta forma, então teríamos uma fragilidade nos nossos dados, ao fim da coleta, uma vez que não saberíamos se metade dos processos de fato não tiveram a pena de multa convolada em outras penas, ou se esses processos tiveram este evento, mas simplesmente, como não havia como documentá-lo, ele foi ignorado. Se quiséssemos manter a alteração na planilha sem gerar essa distorção, a única solução seria reclassificar todos os processos feitos antes dessa mudança, o que é inviável muitas vezes.
Então, para evitarmos retrabalho e a fragilidade nos dados, realizamos o procedimento de pré-teste. Ao fim do pré-teste, temos a versão final das ferramentas de classificação. Além disso, produzimos ao fim desta etapa um documento de padronização das respostas, uma vez que pessoas diferentes podem responder coisas iguais de formas diferentes. Por exemplo, ao se responder o valor de uma multa, uma pessoa pode responder “R$ 10.000,00”, enquanto outra responda apenas “100000” e uma terceira responda “10,000.00”. Essas diferenças na forma de resposta geram problemas na arrumação de dados. Então, a fim de evitar isto, padronizamos a forma como as respostas devem ser colocadas, tanto no formulário, como na planilha.
O pré-teste deste projeto aconteceu entre os dias 07 de julho de 2022 e 20 de julho de 2022 e três pesquisadoras participaram da equipe que realizou essas classificações iniciais.
2.2.2 Coleta automática
Para além da coleta manual, algumas informações foram coletadas automaticamente, por meio de robôs de raspagem de dados. Foram criados dois robôs distintos, um robô para extrair algumas datas que estavam disponíveis no site do SEI e outro para extrair informações a respeito dos conselheiros que julgavam os casos.
2.2.2.1 SEI
A ferramenta de consulta pública do SEI contém todas as movimentações processuais dos recursos apresentados ao CRSFN.2. A ferramenta tem os seguintes campos para realizar pesquisa, conforme a Figura 2.3.
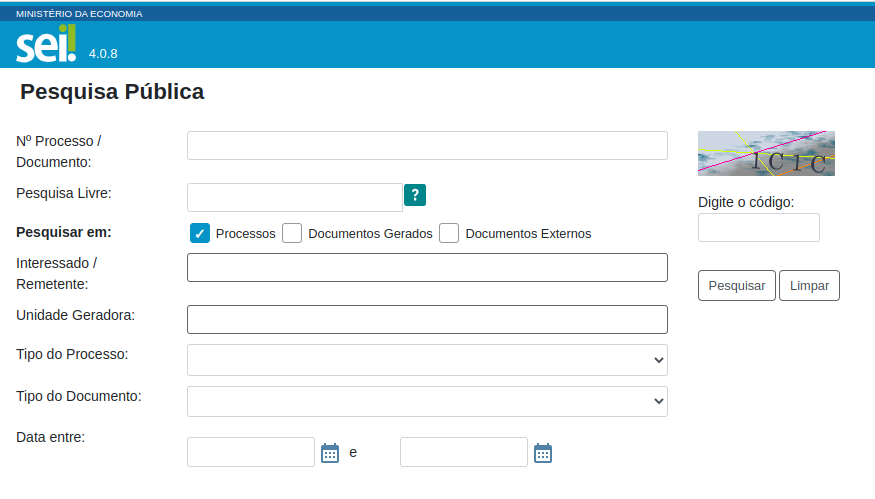
Figura 2.3: Ferramenta de consulta pública do SEI para acessar as movimentações dos processos do CRSFN.
Realizamos a raspagem das movimentações dos processos do CRSFN a partir do número SEI dos processos que havíamos listado3. O número do processo foi utilizado para preencher o campo “N° Processo / Documento”. Para cada processo, obtínhamos a seguinte lista de andamentos processuais, conforme a Figura 2.4.
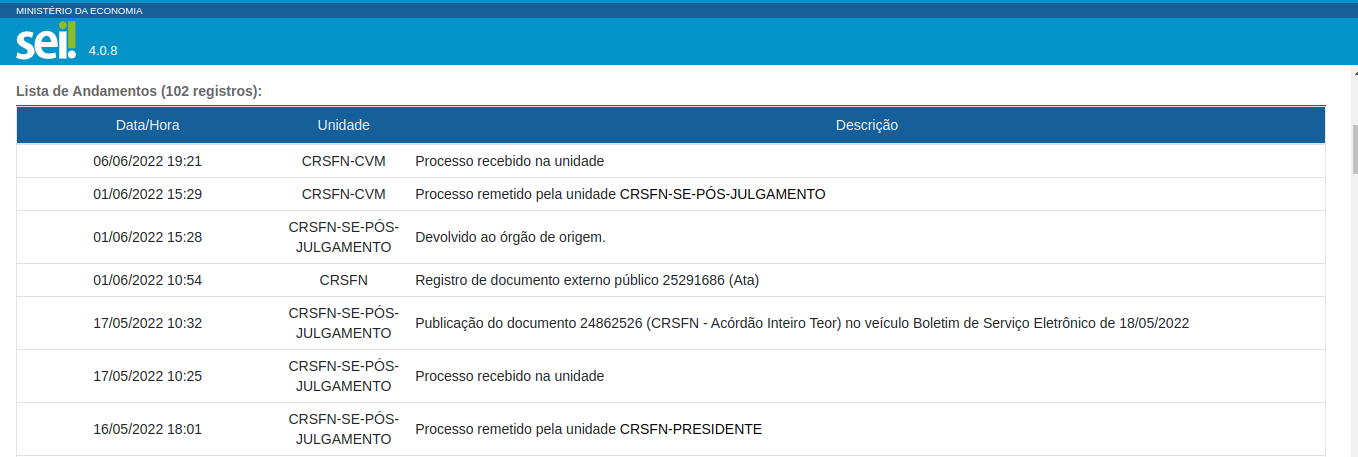
Figura 2.4: Ilustração de como as movimentações apareciam no site do SEI.
O scraper, então, extraiu todas as movimentações de todos os processos. Com isso, criamos uma base intermediária com as colunas conforme a Tabela 2.1.
| Variável | Descrição |
|---|---|
| id | Número SEI do processo |
| data_hora | Data e hora da movimentação |
| unidade | Unidade responsável pela movimentação |
| descricao | Descrição da movimentação |
A partir e todas as movimentações, criamos uma base auxiliar, resumindo algumas informações que eram possíveis de serem extraídas a partir das movimentações processuais, conforme a Tabela 2.2.
| Variável | Descrição |
|---|---|
| id | Número SEI do processo |
| dt_primeira | Data da primeira movimentação |
| dt_autuacao | Data de autuação |
| dt_dist1 | Primeira data de distribuição |
| dt_dist2 | Segunda data de distribuição |
| dt_pauta | Data de inclusão do processo na pauta julgamento |
| dt_julgamento | Data do julgamento |
| parecer_teve | Existência de parecer da PGFN |
| parecer_numero | Número do parecer da PGFN |
| dt_parecer | Data do parecer da PGFN |
2.2.2.2 Conselheiros
O outro scraper que realizamos foi um robô construído para obter as informações a respeito de todos os conselheiros que atuam, ou já atuaram, no CRSFN. Essa informação está disponível no site do CRSFN hospedado no site gov.br do governo federal.4 Este site dispõe as informações da seguinte maneira, conforme a Figura 2.5.
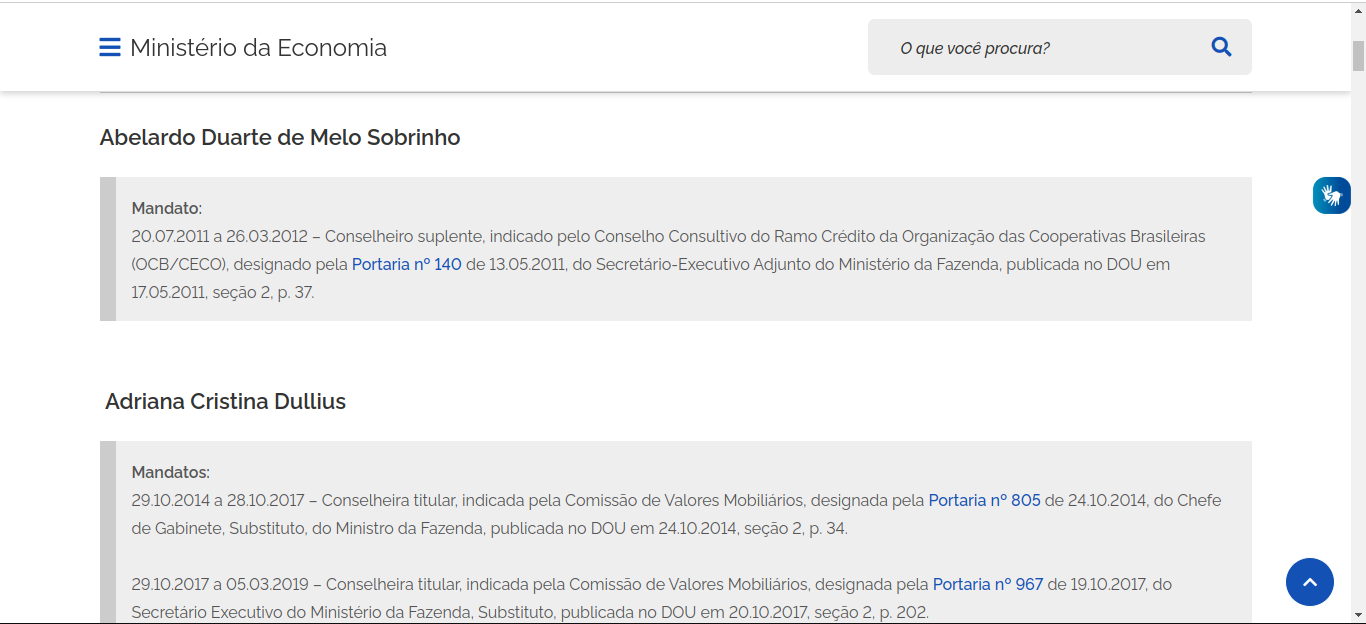
Figura 2.5: Galeria de conselheiros do CRSFN.
O scraper gerou uma base com 180 linhas, em que cada linha significa um conselheiro distinto. Para cada conselheiro foi atribuído um id distinto, que vai de 1 até 180. Além dessa informação, foi possível extrair o nome dos conselheiros, o nome da entidade que o indicou a este cargo e o tipo de indicação (se é de entidades privadas, ou de órgãos públicos). Desta forma, construímos uma base descrita conforme a 2.3
| Variável | Descrição |
|---|---|
| id_conselheiro | ID do conselheiro |
| nome | Nome do conselheiro |
| tipo_indicacao | Tipo de indicação |
| entidade | Nome da entidade que indicou |
| txt | Texto sobre os mandatos |
2.3 Consolidação
A base principal é a base gerada pela classificação do formulário, junto da base gerada pelas planilhas de partes de cada processo. Com a base feita, realizamos diversos cruzamentos que serão explicados a seguir.
Cruzamento entre a base do CRSFN com a base da CVM. Esse cruzamento é o principal para pensarmos nas continuidades ou rupturas entre a CVM e o CRSFN. As bases foram juntadas por meio do número de primeira instância que aparecia no cabeçalho dos acórdãos do CRSFN. Os dados da CVM são aqueles coletados na 1ª Fase do Observatório do Mercado de Capitais5.
Cruzamento entre a base do CRSFN com a base SEI. O cruzamento da base principal do CRSFN com a base construída a partir da consulta pública do SEI foi feito a partir do número SEI dos processos, extraído do cabeçalho dos acórdãos.
Cruzamento entre a base do CRSFN com a base de conselheiros. O cruzamento da base principal do CRSFN com a base de conselheiros foi feito a partir de duas perguntas presentes na planilha de partes, que coletavam o id dos conselheiros presentes na sessão de julgamento e o id dos conselheiros que votaram contra (caso a votação não tenha sido por unanimidade). O id dos conselheiros, então, pôde ser usado para cruzar com as informações específicas de cada conselheiro.
2.4 Análise
O fluxo de obtenção, arrumação e análise de dados segue o ciclo da ciência de dados, descrito na Figura 2.6. O ciclo divide o processo de aprendizado analítico em seis etapas, descritas a seguir.
Primeiro, o formulário de classificação e as planilhas de partes auxiliares são importdados. Em seguida, os dados são arrumados, para mitigar problemas de padronização, obtenção das variáveis de interesse e exclusão de casos que estão fora do escopo de análise, produzindo o que se define como base de dados analítica. A base analítica foi então transformada para produzir as tabelas e gráficos e, quando necessário, são utilizadas como insumo para o ajuste de modelos estatísticos. Finalmente, os resultados obtidos foram comunicados através do presente relatório e de um dashboard interativo, disponível no site do Observatório do Mercado de Capitais.
, adaptado do livro [R for Data Science](https://r4ds.had.co.nz).](assets/img/ciclo-ds.png)
Figura 2.6: Ciclo da ciência de dados. Fonte: Curso-R, adaptado do livro R for Data Science.
O estudo envolveu majoritariamente análises descritivas, como tabelas e gráficos. O propósito das visualizações é verificar as principais perguntas da pesquisa e trazer sumários úteis para a discussão sobre os recursos ao CRSFN. Parte das análises são um pouco mais sofisticadas por conta da natureza dos dados, como gráficos de Kaplan-Meier para analisar tempos, que podem estar censurados.
Todas as análises foram realizadas utilizando-se o software estatístico R, na versão 4.3.2. Os códigos que levam a base de dados analítica para os resultados da pesquisa são reprodutíveis, podendo ser utilizados em projetos futuros de atualização da base.
O site pode ser encontrado neste link. Último acesso 07/12/2022↩︎
A consulta pública do SEI pode ser acessada no seguinte link: https://sei.economia.gov.br/sei/modulos/pesquisa/md_pesq_processo_pesquisar.php?acao_externa=protocolo_pesquisar&acao_origem_externa=protocolo_pesquisar&id_orgao_acesso_externo=0. Último acesso em 08/12/2022↩︎
Os conselheiros antigos podem ser acessados na página da Galeria do Conselho, disponível neste link. Já os conselheiros atuais podem ser acessados na página do Quem é Quem, disponível neste link↩︎