Capítulo 2 Metodologia
Toda pesquisa jurimétrica passa necessariamente por três etapas: listagem de processos, coleta de dados e análise estatística. A etapa da listagem envolve encontrar os números identificadores dos processos que fazem parte da pesquisa, considerando o escopo definido. Já a etapa de coleta envolve acessar os processos através de seus números identificadores, obtendo as informações que são relevantes para o estudo. A terceira etapa envolve a análise estatística dos dados coletados, realizando os cruzamentos necessários para atingir os objetivos da pesquisa.
2.1 Listagem de processos
A listagem de processos envolve três passos principais: identificação das fontes de dados, acesso aos processos e aplicação dos filtros de escopo. O primeiro passo envolve encontrar todos os meios para consulta dos processos de interesse. O segundo passo envolve desenvolver métodos computacionais para acessar e consolidar as informações a respeito desses processos. O último passo envolve adequar os dados resultantes ao escopo da pesquisa, excluindo casos que não farão parte da população em análise.
2.1.1 Fontes de dados
Para buscar as fontes disponíveis, o primeiro passo é compreender como o PAS é organizado nos sistemas da CVM em cada etapa processual.
O fluxo simplificado do PAS foi descrito na Figura 2.1. O primeiro registro do processo em sistemas publicamente acessíveis ocorre no momento da citação dos acusados. Em seguida, o processo pode seguir para dois caminhos: apresentação de TC ou julgamento. O TC apresentado não é acessível publicamente, restando disponíveis somente o Termo de Compromisso Celebrado (TCC) em caso de conciliação frutífera, ou decisão de rejeição do TC, disponível somente através das atas de reuniões do colegiado.1 Neste último caso, o processo ainda iria para julgamento final do PAS.
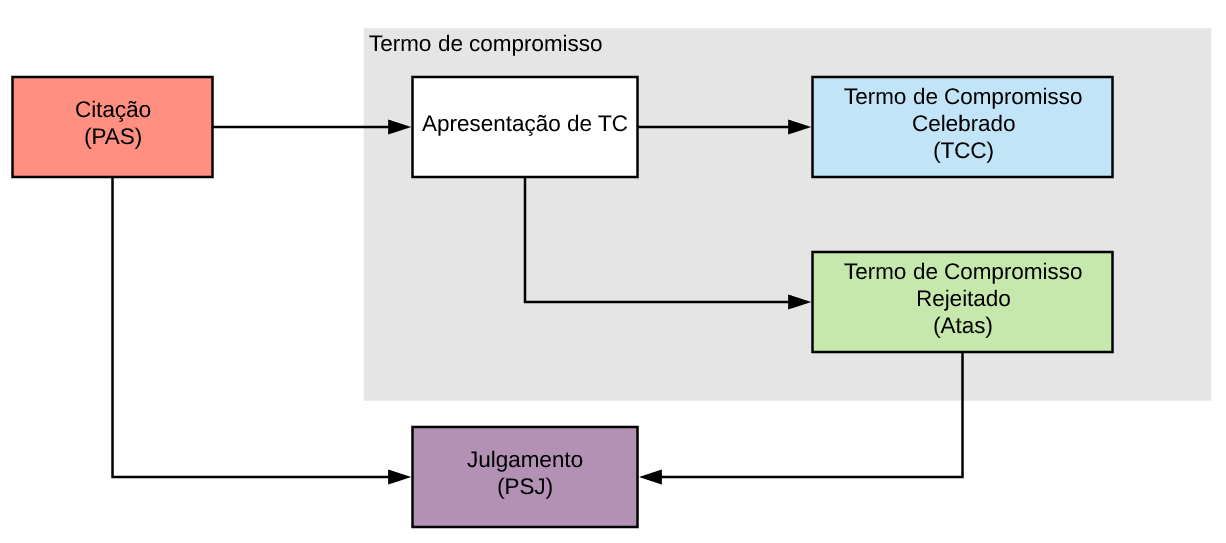
Figura 2.1: Diagrama simplificado do fluxo do PAS.
Considerando os pontos supracitados, para o presente estudo, foram levantadas quatro fontes distintas de dados, descritas a seguir.
PAS. Trata-se da consulta de Processos Administrativos Sancionadores da CVM2. A ferramenta permite a consulta de processos individuais, bem como a listagem de processos a partir de palavras-chave aplicadas às ementas, objeto ou acusados.

Figura 2.2: Ferramenta de consulta do PAS.
TCC. Trata-se da consulta de Termos de Compromisso Celebrados da CVM3. A ferramenta permite a listagem completa de processos, sem necessidade de utilizar palavras-chave.
Figura 2.3: Ferramenta de consulta de termos de compromisso celebrados.
PSJ. Trata-se da consulta de Processos de Sancionadores Julgados da CVM4. A ferramenta permite a listagem completa de processos, sem necessidade de utilizar palavras-chave.
Figura 2.4: Ferramenta de consulta de processos sancionadores julgados.
ATAS. Trata-se da consulta de atas de reuniões do colegiado da CVM5. A ferramenta permite realizar consultas tanto das decisões tomadas quanto das atas de reuniões que contêm todas as decisões. As decisões podem ser referentes a apreciação de propostas de TCs, mas também de outras decisões relativas a PAS ou mesmo outros processos administrativos sem caráter sancionador. No presente estudo, foram consideradas somente decisões de apreciação de termos de compromisso.
Figura 2.5: Ferramenta de consulta de atas de reuniões do colegiado.
2.1.2 Acesso e consolidação
O acesso aos dados de PAS foi realizado através da construção de ferramentas de raspagem de dados, considerando as quatro fontes descritas na subseção anterior.
O trabalho foi realizado em três passos. O ponto de partida foi a ferramenta de consulta PAS, que contém a lista de todos os processos de interesse da pesquisa. Em seguida, foram obtidos, também através de ferramentas de raspagem, todos os dados de TCC, PSJ e ATAS. Finalmente, as informações dos quatro sistemas foram cruzadas, com o fim de obter todas as informações disponíveis para cada processo.
Para o primeiro passo, infelizmente a consulta processual não permite a pesquisa por termos vazios, o que dificultou a listagem completa de processos. Além disso, quando uma consulta ultrapassa mais de mil registros, a ferramenta de pesquisa trunca os resultados. Para superar essa barreira, foi considerada a seguinte partição de possíveis termos de pesquisa: “a a”, “a b”, “a c”, …, “a z”, “b a”, “b b”, …, “b z”, …, “z a”, “z b”, …, “z z”. Com essa partição, garantimos que todos os processos fossem contemplados, e ainda que cada pesquisa contenha menos de mil resultados na busca.
Para o segundo passo, foram baixados não só os dados semiestruturados em HTML, como também todas as decisões contendo o inteiro teor ou do termo de compromisso celebrado. Os dados foram armazenados em disco para facilitar a coleta manual de dados, realizada pelos pesquisadores da ABJ.
O terceiro passo foi o mais complexo da etapa de listagem, por dois motivos.
Primeiro, os números identificadores dos processos sofreram uma alteração no ano de 2016 para o formato do Sistema Eletrônico de Informações (SEI), o que dificultou a associação entre os PAS de cada fonte de dados. Para resolver esse problema, as diferentes fontes de dados foram associadas usando todos os possíveis formatos de numeração, sendo necessário ainda arrumar a formatação da numeração antiga, que pode divergir em cada fonte de dados.
Além do problema da multiplicidade de numerações, no caso das ATAS, o número do processo não aparece em metadados dos processos. Para resolver esse problema, foi necessário buscar os números no inteiro teor da decisão para associá-los aos números disponíveis no PAS. Para a busca, foram consideradas somente decisões de apreciação de termos de compromisso.
Para superar ambos os problemas, foram utilizados fluxos de classificação semiautomáticos, a partir de técnicas de mineração de texto aplicadas aos documentos dos processos. A classificação a partir de técnicas de mineração de texto segue o fluxo de trabalho descrito abaixo.
Determinar todas as variáveis que queremos extrair das bases (ex. ano de distribuição; ementa; desfecho).
Para cada variável:
2.1. Realizar a leitura (manual) de uma amostra de processos, sem necessariamente seguir um procedimento amostral adequado, anotando algumas regras lógicas capazes de extrair a variável de forma automática.
2.2. Aplicar a regra lógica aos dados.
2.3. Verificar quantos casos são extraídos pela regra lógica.
2.4. Voltar ao passo 2.1 somente com a base de dados de casos não testados, com o objetivo de buscar de novas informações, até que a abrangência do conjunto de regras lógicas definidas seja satisfatória.
Verificar a qualidade das classificações a partir da leitura de uma amostra de processos já classificados. Se encontrar problemas, voltar ao passo 2.1 com a base completa. Caso contrário, passar para a próxima variável.
Verificar se a classificação de uma variável modifica de forma incorreta a classificação de outras variáveis. Se sim, voltar ao passo 2 com essas novas informações. Caso contrário, continuar.
Verificar diversos tipos de inconsistências da base, como ordem de datas, confrontamento com dados conhecidos etc. Caso o resultado não seja satisfatório, voltar ao passo 2. Caso contrário, finalizar.
O fluxo de classificação foi esquematizado na Figura 2.6. Note que o fluxo envolve várias fases de leitura manual dos processos. Os códigos gerados usando esse fluxo são reprodutíveis, mas não necessariamente replicáveis. Isso significa que o mesmo algoritmo pode não ser eficaz para bases de dados referentes a escopos distintos. Por exemplo, o mesmo conjunto de regras para provavelmente precisaria ser aprimorado no momento de atualizar a base de dados.
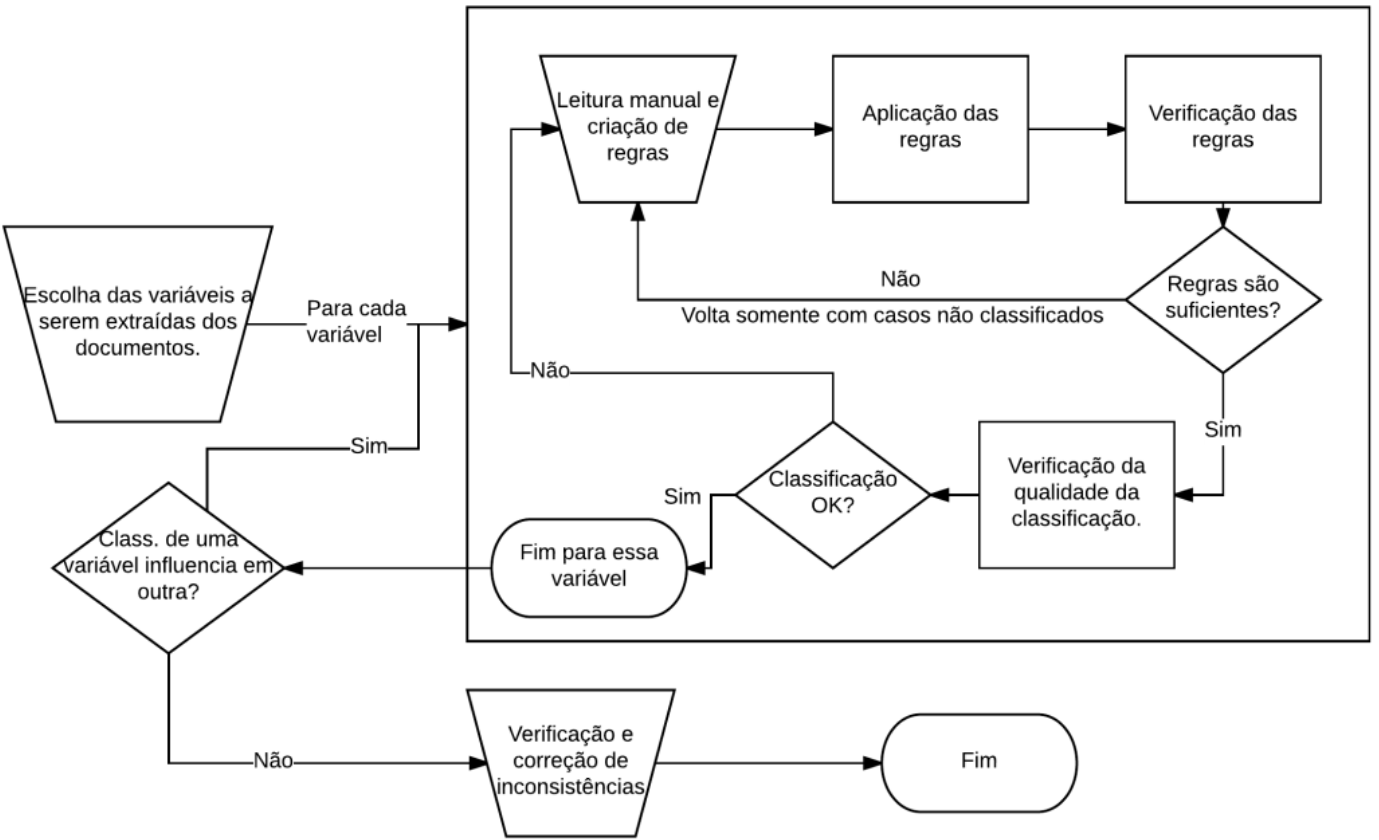
Figura 2.6: Fluxo de classificação dos documentos simplificado.
2.1.3 Filtros de escopo
Por se tratar de um estudo retrospectivo, só foram considerados na base os PAS com algum PSJ ou TCC. Isso significa que foram retirados da base os casos em que não houve decisões nem termos de compromisso celebrados.
A Tabela 2.1 mostra as quantidades de processos para cada combinação de existência de TCC e PSJ. Do total de 1746 casos identificados, 492 (28%) foram excluídos por ainda estarem ativos.
| Categoria | N | % |
|---|---|---|
| Tem TCC e PSJ | 62 | 3.5% |
| Tem PSJ e não tem TCC | 1010 | 57.4% |
| Tem TCC e não tem PSJ | 287 | 16.3% |
| Não tem TCC nem PSJ | 402 | 22.8% |
Todos os processos ainda passaram por inspeção manual para verificação do escopo e das características dos processos durante a inspeção manual. No final da coleta, foram considerados na análise 1433 casos. A coleta dos dados é o tema que descrevemos a seguir.
2.2 Coleta
A coleta de dados envolve a leitura dos documentos de todos os processos resultantes da aplicação dos filtros de escopo e o preenchimento de fichas de classificação. Para isso, adotou-se uma metodologia em três passos: pré-teste, classificação e diagnóstico.
No pré-teste, foram analisados 30 casos no total, sendo cada processo analisado por três pesquisadores distintos. O objetivo do pré-teste foi compreender questões com problemas de interpretabilidade ou alto grau de subjetividade e antecipar possíveis problemas do questionário. A partir do pré-teste, diversos aprimoramentos foram realizados no formulário de classificação final, como a fixação das categorias de uma série de variáveis que estavam com resposta aberta. O estudo Prado, Silva, and Santos (2019) foi utilizado como base para definição das categorias. Além disso, foi possível antecipar que alguns marcos temporais de interesse normalmente não estão presentes nos documentos dos processos. O pré-teste foi finalizado em dezembro de 2019.
Durante a etapa de classificação, cada pesquisador recebeu um conjunto de processos para analisar e uma pasta contendo todas as informações baixadas das fontes de dados mencionadas. Dessa forma, os pesquisadores não precisaram procurar os processos nas ferramentas de consulta da CVM, o que acelerou o trabalho de classificação manual. Esta etapa foi foi realizada entre janeiro e março de 2020.
O formulário de classificação aplicado utilizou tecnologia Google Forms, pela sua facilidade com a integração com as ferramentas computacionais da ABJ. O formulário possui 40 campos, sendo uma parte preenchida automaticamente com metadados do processo (como número do processo e número identificador interno) e parte se desdobrava em vários campos (como os nomes dos participantes da votação). O formulário também envolve uma planilha Excel auxiliar, para inclusão de todas as informações das partes, incluindo decisões, multas, CNPJ das pessoas jurídicas e forma de participação. A planilha possui controle de entrada de informações, com categorias bem definidas para cada campo sempre que possível, com o objetivo de evitar inconsistências na análise dos dados.
Durante a etapa de diagnóstico, os estatísticos da equipe extraíram a base de dados construída pelos pesquisadores em Direito, buscando inconsistências na classificação. Foi constatado que i) em alguns casos, não foi possível encontrar a decisão do colegiado sobre a apreciação do temo de compromisso, mesmo que tal decisão fosse mencionada no PSJ e ii) alguns casos estavam ativos para algumas partes, mas encerrados para outras.
2.3 Análise
O fluxo de obtenção, arrumação e análise de dados segue o ciclo da ciência de dados, descrito na Figura 2.7. O ciclo divide o processo de aprendizado analítico em seis etapas, descritas a seguir.
Primeiro, o formulário de classificação e as mais de mil planilhas de partes auxiliares são extraídas dos questionários. Em seguida, os dados são arrumados, para mitigar problemas de padronização, obtenção das variáveis de interesse e exclusão de casos que estão fora do escopo de análise, produzindo o que se define como base de dados analítica. A base analítica foi então transformada para produzir as tabelas e gráficos e, quando necessário, são utilizadas como insumo para o ajuste de modelos estatísticos. Finalmente, os resultados obtidos foram comunicados através do presente relatório e de um dashboard interativo, disponível no site do Observatório do Mercado de Capitais.
, adaptado do livro [R for Data Science](https://r4ds.had.co.nz).](assets/img/ciclo-ds.png)
Figura 2.7: Ciclo da ciência de dados. Fonte: Curso-R, adaptado do livro R for Data Science.
O estudo envolveu majoritariamente análises descritivas, como tabelas e gráficos. O propósito das visualizações é verificar as principais perguntas da pesquisa e trazer sumários úteis para a discussão sobre os PAS.
Para responder algumas perguntas específicas, foi necessário utilizar modelos estatísticos de regressão. Os modelos foram utilizados para verificar as variáveis mais importantes para predizer o desfecho dos processos quando há PSJ, principalmente para a absolvição. Para isso, foram ajustados três modelos distintos: regressão logística (McCullagh 2018), regressão logística com regularização lasso (Tibshirani 1996) e florestas aleatórias (Breiman 2001). As bases foram separadas em treino e teste, sendo a primeira para ajuste do modelo e a segunda para verificar a acurácia. O modelo escolhido como final foi aquele com maior acurácia, sendo então utilizado para intepretação dos resultados.
Todas as análises foram realizadas utilizando-se o software estatístico R, na versão 4.2.2. Os códigos que levam a base de dados analítica para os resultados da pesquisa são reprodutíveis, podendo ser utilizados em projetos futuros de atualização da base.
Referências bibliográficas
Em 2020, a CVM passou a disponibilizar também a lista de TC rejeitados.↩︎
http://sistemas.cvm.gov.br/?PAS. Último acesso em 17/05/2020.↩︎
http://www.cvm.gov.br/termos_compromisso/index.html. Último acesso em 17/05/2020.↩︎
http://www.cvm.gov.br/sancionadores/sancionador.html. Último acesso em 17/05/2020.↩︎
http://www.cvm.gov.br/decisoes/index.html. Último acesso em 17/05/2020.↩︎