Capítulo 2 Metodologia
Toda pesquisa jurimétrica passa necessariamente por três etapas: listagem de processos, coleta de dados e análise estatística. A etapa da listagem envolve encontrar os números identificadores dos processos que fazem parte da pesquisa, considerando o escopo definido. Já a etapa de coleta envolve acessar os processos através de seus números identificadores, obtendo as informações que são relevantes para o estudo. A terceira etapa envolve a análise estatística dos dados coletados, realizando os cruzamentos necessários para atingir os objetivos da pesquisa.
2.1 Listagem de processos
A listagem de processos envolve três passos: identificação das fontes de dados, acesso aos processos e aplicação dos filtros de escopo. O primeiro passo envolve encontrar todos os meios para consulta dos processos de interesse. O segundo passo envolve desenvolver métodos computacionais para acessar e consolidar as informações a respeito desses processos. O último passo envolve adequar os dados resultantes ao escopo da pesquisa, excluindo casos que não farão parte da população em análise.
A fonte de dados utilizada para listar os processos foram os Diários de Justiça Eletrônicos (DJE) disponibilizados no site do TJSP. Trata-se de arquivos PDF com milhares de página, contendo informações de toda a tramitação processual diária do estado. Os arquivos foram baixados utilizando-se técnicas de raspagem de dados e depois transformados em texto para permitir a identificação de processos.
A identificação dos processos consiste em filtrar as páginas dos DJEs que contêm alguma menção a processos de falências. O filtro considerou as palavras-chave “falência” (com e sem acentuação) e “falida”. As páginas assim obtidas foram então processadas para a listagem dos números de processos ali presentes.
Finalmente, a filtragem de escopo envolveu a consulta automatizada dos processos identificados no passo anterior na consulta do TJSP. Foram mantidos todos os processos com classe processual “Falência de Empresários, Sociedades Empresáriais, Microempresas e Empresas de Pequeno Porte”. Infelizmente, a taxonomia do assunto dos processos não é específica o suficiente para identificar de forma clara os processos principais das falências. Por esse motivo, foi necessário verificar manualmente se os processos listados eram, de fato, processos de falência. Nesse processo, quase 15% dos processos listados foram descartados.
2.2 Coleta
A coleta de dados envolve a leitura dos documentos de todos os processos resultantes da aplicação dos filtros de escopo e o preenchimento de fichas de classificação. Para isso, adotou-se uma metodologia em três passos: pré-teste, classificação e diagnóstico.
No pré-teste, foram analisados 33 casos no total, sendo cada processo analisado por três pesquisadores distintos. O objetivo do pré-teste foi compreender questões com problemas de interpretabilidade ou alto grau de subjetividade e antecipar possíveis problemas do questionário. A partir do pré-teste, diversos aprimoramentos foram realizados no formulário de classificação final, como a fixação das categorias de uma série de variáveis que estavam com resposta aberta. Além disso, foi possível antecipar que alguns marcos temporais de interesse normalmente não estão presentes nos documentos dos processos. O pré-teste foi finalizado em abril de 2020.
Durante a etapa de classificação, cada pesquisador recebeu um conjunto de processos para analisar. Os pesquisadores então se utilizavam das ferramentas de consulta do TJSP, para pesquisar sobre os processos e preencher o formulário de classificação. Esta etapa foi iniciada em maio de 2020 e encontra-se em curso até o momento de escrita do presente relatório.
O formulário de classificação aplicado utilizou tecnologia Google Forms, pela sua facilidade com a integração com as ferramentas computacionais da ABJ. O formulário possui mais de cem campos, sendo uma parte preenchida automaticamente com metadados do processo (como número do processo e classe processual) e outra parte preenchida manualmente pelos pesquisadores. As várias partes do questionário se desdobravam em vários campos (como as descrições dos bens e valores das avaliações). O formulário também envolvia planilhas Excel auxiliares, para inclusão de todas as informações das partes, alienações e leilões. As planilhas possuem controle de entrada de informações, com categorias bem definidas para cada campo sempre que possível, com o objetivo de evitar inconsistências na análise dos dados.
O questionário segue o fluxo do diagrama na Figura 2.1. O processo de falência possui diversos momentos de encerramento por ausência de eventos, como decretação, arrecadação de bens e o encerramento da falência propriamente dito.
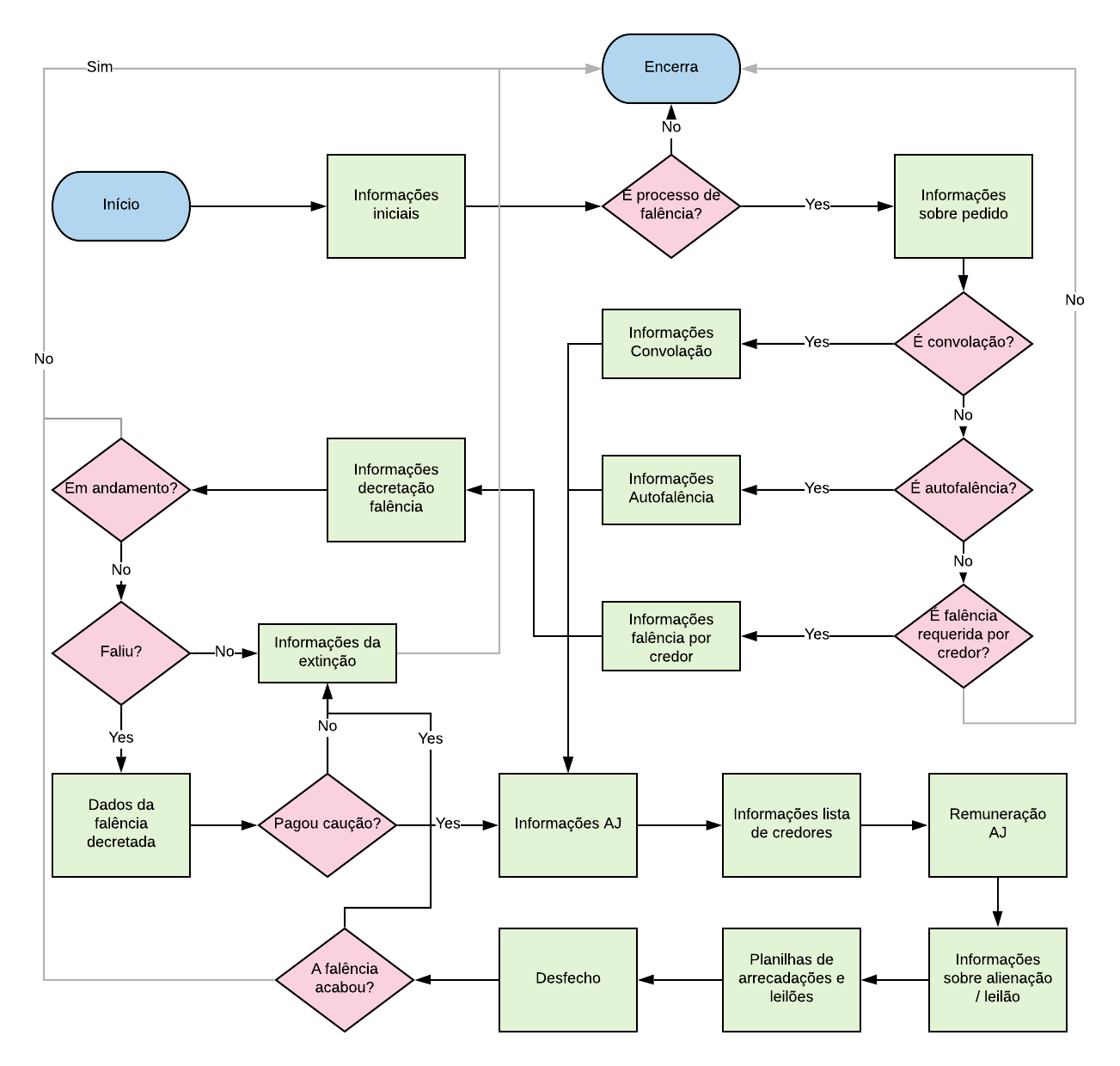
Figura 2.1: Diagrama representando o funcionamento do questionário.
Durante a etapa de diagnóstico, os estatísticos da equipe extraíram a base de dados construída pelos pesquisadores, buscando inconsistências na classificação. Foi constatado que i) na maior parte dos casos, não foi possível encontrar informações sobre as classes de credores efetivamente pagas ao longo do processo de falências e ii) muitos casos ainda estavam aguardando a primeira arrecadação no momento da análise.
2.3 Análise
O fluxo de obtenção, arrumação e análise de dados segue o ciclo da ciência de dados, descrito na Figura 2.2. O ciclo divide o processo de aprendizado analítico em seis etapas, descritas a seguir.
Primeiro, o formulário de classificação e as planilhas auxiliares são extraídas dos questionários. Em seguida, os dados são arrumados, para mitigar problemas de padronização, obtenção das variáveis de interesse e exclusão de casos que estão fora do escopo de análise, produzindo o que se define como base de dados analítica. A base analítica foi então transformada para produzir as tabelas e gráficos e, quando necessário, são utilizadas como insumo para o ajuste de modelos estatísticos. Finalmente, os resultados obtidos foram comunicados através do presente relatório e de um dashboard interativo, disponível no site do Observatório das Falências.
, adaptado do livro [R for Data Science](https://r4ds.had.co.nz).](assets/img/ciclo-ds.png)
Figura 2.2: Ciclo da ciência de dados. Fonte: Curso-R, adaptado do livro R for Data Science.
O estudo envolveu majoritariamente análises descritivas, como tabelas e gráficos. O propósito das visualizações é verificar as principais perguntas da pesquisa e trazer sumários úteis para a discussão sobre os processos de falências.
Todas as análises foram realizadas utilizando-se o software estatístico R, na versão 4.2.1. Os códigos que levam a base de dados analítica para os resultados da pesquisa são reprodutíveis, podendo ser utilizados em projetos futuros de atualização da base.