2.5 Estudo 3: CAPTCHAs
Apesar dos sistemas jurídicos serem públicos, seus dados não são acessíveis. Muitas vezes o acesso às páginas web são limitadas através de bloqueios de IP e
Algumas justificativas para a existência de CAPTCHAs são: i) não onerar os sistemas ou ii) a ideia de que assim estão protegendo as pessoas. O primeiro argumento é frágil pois ambos poderiam ser resolvidos através de uma API de acesso público dos tribunais, ou mesmo uma API paga. O segundo argumento também é ruim, pois, ainda que limitado, esses dados serão obtidos e utilizados. Limitar o acesso só aumenta o custo para construção dessas bases, direcionando o poder para as empresas que têm mais dinheiro para investir nisso, causando viés no acesso à informação.
Fazendo curta uma história longa, se um dado é público, ele deve ser acessível.
Nos trabalhos da ABJ, esbarramos com CAPTCHAs inúmeras vezes. Recentemente, descobrimos formas de resolver CAPTCHAs automaticamente utilizando modelos estatísticos. Esses modelos são da recente (ou não) classe de modelos de deep learning, uma área que cresceu exponencialmente nos últimos anos.
Incluímos esse exemplo no curso por dois motivos. Apesar de não ser um modelo jurimétrico, trata-se de um problema presente no contexto da jurimetria, logo é um conhecimento útil. Além disso, a técnica utilizada para quebrar CAPTCHAs é muito interessante e poderia ser adaptada para diversos contextos, inclusive estudos jurimétricos.
Nossas soluções para quebrar captchas foram consolidadas num pacote chamado decryptr. Vamos discutir brevemente como ele foi criado e como usar. Também discutiremos superficialmente o modelo de redes neurais utilizado e como criar o seu próprio modelo.
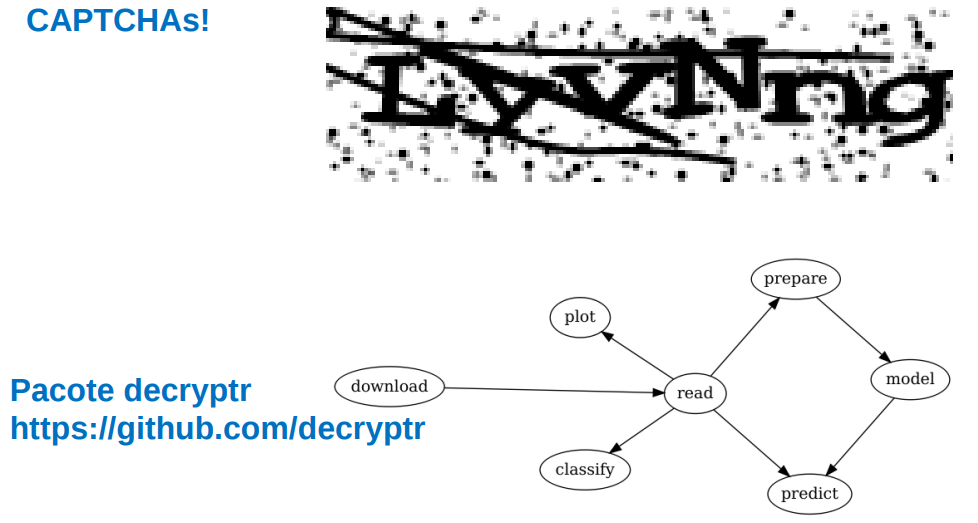
Veja um quebrador de captcha em funcionamento:
